基于协同过滤算法的新闻推荐系统设计与实现
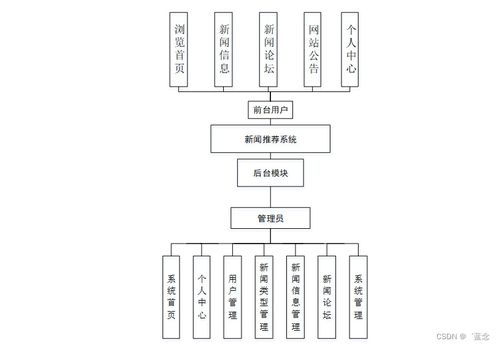
随着互联网信息爆炸式增长,用户如何从海量新闻中高效获取个性化内容成为亟待解决的问题。个性化推荐系统,特别是基于协同过滤算法的推荐技术,因其能有效挖掘用户潜在兴趣,已成为解决信息过载的关键手段。本项目以SpringBoot为后端框架,设计并实现了一个基于协同过滤算法的新闻推荐系统(项目编号:9k0339,面向计算机系统服务领域),旨在为用户提供精准、实时的个性化新闻阅读体验。
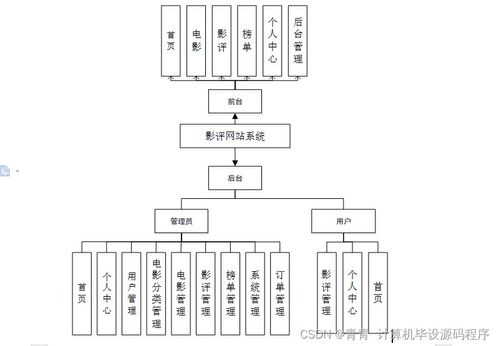
一、 系统总体设计
系统采用经典的三层架构:表示层、业务逻辑层和数据访问层,确保系统的高内聚、低耦合。
- 表示层:采用HTML5、CSS3和JavaScript构建响应式前端页面,并集成Thymeleaf模板引擎,实现动态内容渲染,确保用户在不同设备上获得一致的交互体验。
- 业务逻辑层:作为核心,基于SpringBoot框架构建。该层负责处理用户请求、执行业务规则,并集成了协同过滤推荐算法模块。
- 数据访问层:使用Spring Data JPA简化数据库操作,与MySQL数据库进行交互,持久化存储用户、新闻、评分、浏览历史等关键数据。
二、 核心算法:协同过滤的实现
协同过滤是本系统的核心,主要分为基于用户的协同过滤和基于物品的协同过滤两种策略。
- 基于用户的协同过滤:其核心思想是“相似用户喜欢相似物品”。系统通过计算用户之间的相似度(如余弦相似度、皮尔逊相关系数),为目标用户找到兴趣相近的“邻居”用户,然后将邻居喜欢而目标用户未浏览过的新闻推荐给他。具体流程包括构建用户-新闻评分矩阵、计算用户相似度、生成推荐列表。
- 基于物品的协同过滤:其核心思想是“喜欢物品A的用户也可能喜欢与A相似的物品B”。系统计算新闻之间的相似度,根据用户的历史行为(点击、阅读时长、评分),推荐与其过去喜欢新闻相似的新闻。这种方式在新闻物品相对稳定、用户增长较快的场景下更具优势。
在实现中,系统综合了两种策略,并引入时间衰减因子,对近期行为赋予更高权重,以适应用户兴趣的动态变化,提高推荐的时效性和准确性。
三、 系统功能模块
系统主要包含以下功能模块:
- 用户管理模块:支持用户注册、登录、个人信息维护及偏好设置。
- 新闻管理模块:实现新闻信息的录入、分类、标签化、查询与展示。新闻数据可通过爬虫接口或手动方式导入。
- 行为采集模块:隐式收集用户的点击、阅读时长、收藏、评分等行为数据,作为推荐算法的重要输入。
- 推荐引擎模块:系统的核心,实时或离线运行协同过滤算法,为登录用户生成个性化新闻推荐列表,并在首页“为你推荐”栏目展示。
- 热门与分类推荐模块:提供基于全局热度的新闻排行和按新闻类别(如科技、体育、财经)的浏览功能,作为个性化推荐的补充,解决新用户的“冷启动”问题。
- 后台管理模块:供管理员管理用户、新闻数据,监控系统运行状态,调整推荐算法参数。
四、 系统实现与关键技术
- 后端框架:采用SpringBoot,简化了配置和部署,内嵌Tomcat服务器,便于快速开发和独立运行。
- 数据处理:使用MySQL存储结构化数据。对于大规模用户行为数据,为提升相似度计算效率,系统采用基于内存的缓存技术(如Redis)存储用户最近的行为向量和临时计算结果。
- 算法集成:使用Java实现协同过滤算法核心逻辑,并通过SpringBoot的服务组件进行封装和调用。相似度计算部分进行了优化,避免全量计算。
- 部署与服务:项目最终打包为可执行的JAR文件,可轻松部署到各类计算机系统服务环境中,提供稳定、高效的推荐服务。
五、 项目与展望
本项目成功构建了一个功能完整的新闻推荐系统原型。SpringBoot框架的使用极大地提升了开发效率,而协同过滤算法的有效集成实现了基本的个性化推荐。系统能够根据用户的历史行为,不断学习和调整,提供越来越精准的新闻内容。
系统可从以下方面进行优化与扩展:
- 算法融合:结合基于内容的推荐(分析新闻文本特征),形成混合推荐模型,进一步提升推荐质量,特别是解决新闻物品的冷启动问题。
- 实时性提升:引入流处理框架(如Flink、Kafka),实现对用户实时行为的快速响应,做到秒级推荐更新。
- 深度学习应用:探索使用神经网络(如Wide & Deep、NCF)进行更复杂的特征交叉和兴趣建模。
- 可扩展性增强:在用户量和新闻量剧增时,考虑采用分布式计算框架(如Spark MLlib)来加速大规模矩阵运算。
本“基于协同过滤算法的新闻推荐系统”不仅是一次SpringBoot技术的工程实践,更是对推荐系统核心原理的深入应用,为构建更智能的信息服务平台奠定了基础。
如若转载,请注明出处:http://www.kuaikanzixun.com/product/50.html
更新时间:2026-02-27 07:21:01